vCX-Hard: Benchmarking Leading AI Models on Real Contact Center Calls

Introducing vCX-Hard, a Retell benchmark that ranks leading models on real contact center calls, measuring two capabilities that determine whether a voice agent succeeds: staying grounded in the truth and taking the right action. Built from proprietary production call data, vCX-Hard evaluates model performance where it matters most. Even the best model today clears only about 88% on the hardest turns, which is exactly why model choice matters.
Customers ask us one question more than any other: which model should I use for my voice agent? For a long time the honest internal answer was a name and a shrug. For a platform that runs millions of real customer calls, that is not good enough.
A call center agent lives or dies on two abilities, and only two:
Public benchmarks rarely test both at once, and almost never on the conditions of a live phone call. The data that can is hard to get. A single company's own call logs are not diverse enough to rank models with confidence. Retell sits on real, diverse production traffic across many industries and deployments, at the volume it takes to separate one model from another. That is the one ingredient a trustworthy call center benchmark needs, and it is the one most teams cannot assemble.
The name says what it is. The lowercase v is for voice. CX is customer experience, the everyday work of a call center agent. Hard is the method: we grade only on the hardest turns from real production traffic, the moments where models actually pull apart. On the full distribution of production calls, most frontier models already clear 90 percent, which tells you nothing useful. The hard slice is where a benchmark earns its keep.
Every case is mined from real production calls, not written by hand or generated synthetically. We score models on the two axes that decide a call:
We evaluated 50 configurations spanning 27 models. Because voice agents in production run with reasoning off, for latency, we report two views throughout: production (reasoning off, what runs on live calls) and best (medium reasoning, a ceiling for how much reasoning would buy). GPT-5.5 leads both, reaching 84.8 percent non-hallucination in production and 88.0 percent at its best. No model is close to solved, which is exactly the point.
We sampled production call traffic between February 6 and May 1, 2026, in 30-minute windows roughly every 15 days, drawn from organizations with more than 1,000 calls in the prior three months. Crucially, we sampled at the organization level, so that a few high-volume orgs do not dominate the set. That is what keeps the distribution broad across real deployments rather than skewed toward any one customer.
From that traffic we curated two sets of difficult cases: a hallucination set of 2,075 cases and a tool-calling set of 1,514 cases. Each case is mined through a multi-stage pipeline. Lightweight pre-classifiers flag candidate turns (numeric claims, pre-transfer moments, tool errors, repeated or missing calls), an LLM classifier then confirms whether a real failure occurred and labels its category and severity, a second pass re-checks the specific turn, and finally a correct reference solution is generated for grading.
The failure taxonomy itself is informative. On the hallucination side, the dominant problem is not exotic. Agents fabricate or misstate policy far more than anything else.

Tool-calling failures cluster just as tightly. Of 1,514 cases, the two largest categories are missing a needed call (897) and firing an unnecessary one (520). Wrong-tool selection is almost nonexistent (2 cases). In other words, models rarely pick the wrong tool. They fail at judgment: knowing when to act and when to hold.
Grading uses an LLM council: a panel of leading frontier models that scores each case against a descriptive rubric and a generated reference solution. Using several strong judges rather than one keeps the evaluation from inheriting any single model's blind spots, and disagreements are reconciled within the panel.
Because absolute scores shift with the rubric and the judges, we treat the ranking, not the exact number, as the signal.
The top score is about 88 percent, and that is by design. If we graded on the full production distribution, almost every frontier model would land above 90 percent and the leaderboard would tell you nothing. Easy calls are easy for everyone.
So vCX-Hard is built from the hardest turns, the moments where models actually diverge. This is how every serious benchmark works. A math benchmark uses competition problems, not the arithmetic a typical user types in. The goal is not a flattering number. The goal is a number you can compare across models, and across time as new models ship.
We show every leaderboard two ways: production, with reasoning off, which is what runs on live calls, and best, each model at its strongest reasoning setting, which shows the ceiling. On non-hallucination, GPT-5.5 leads both. In production the GPT-5 line and gemini-3.1-pro sit at the top; turning reasoning on lifts the same names a few points and reshuffles the chase behind them.
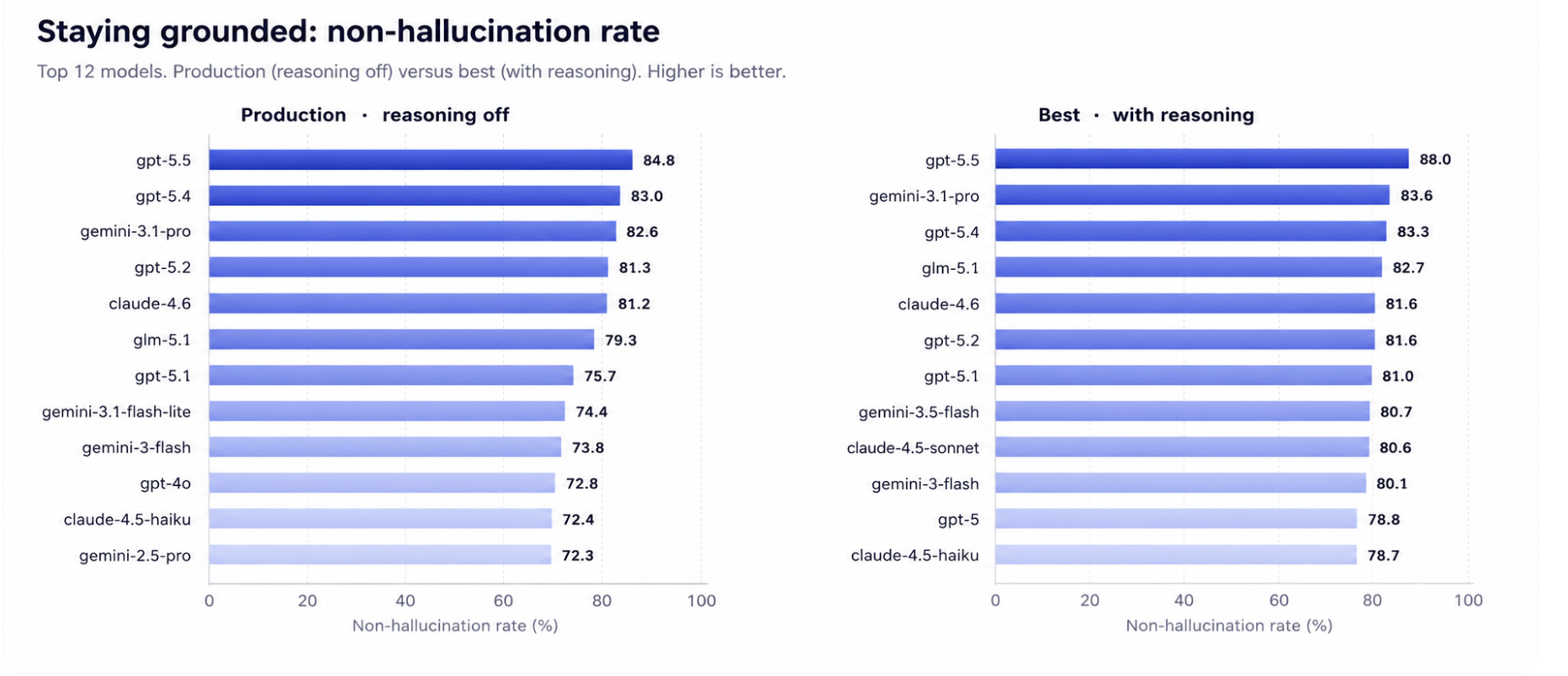
Tool-call correctness is where the two views diverge most. With reasoning on, GPT-5.5 leads. But in production, where it actually runs, GPT-5.5's tool-calling falls from 88.3 to 75.6 percent, and gemini-3.1-pro becomes the best tool-caller by a clear margin, holding 85.7 percent with reasoning off. If your agent runs reasoning off, the strongest model is not the same one.

Three patterns stand out across the full set.
1. Reasoning is the gap between the two views. Turning reasoning on lifts scores on nearly every model, by about 5 points on average for non-hallucination. GPT-5.5 climbs from 84.8 to 88.0 percent once it reasons before it speaks. The cost is latency, which is why most production agents leave it off, and why the production view is the one to plan around.

2. Grounding and action are different skills. The two axes do not rank alike. A model strong on grounding can be middling on tool-calling and the reverse. GPT-5.4 ranks near the top on grounding but outside the top ten on tool-calling, while claude-4.5-sonnet is the opposite. Choosing a model is really a question of which failure your customers can least afford.
3. No model is safe yet. Even at its best the leader still misses about one in eight of the hardest turns on each axis, and in production it misses more. The gap between a benchmark score and a deployment you can trust is exactly the work the platform does on top of the model.
Looking across model generations, the frontier is moving in the right direction. From GPT-4o to GPT-5.5, non-hallucination rose from 72.8 to 88.0 percent, with tool-calling improving on a similar arc.
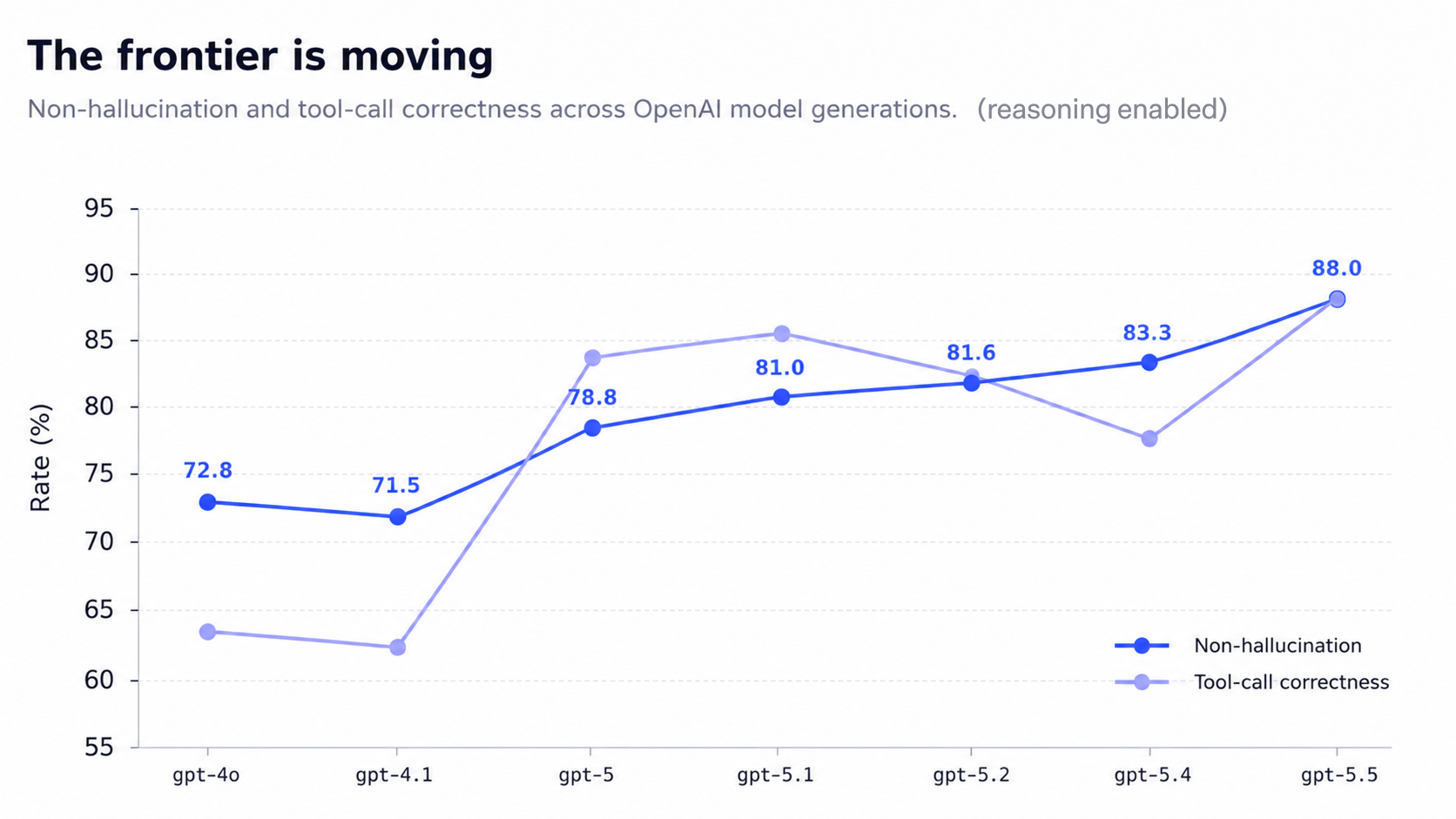
Production (reasoning off, what runs live) and best (strongest reasoning setting) for each model, sorted by production non-hallucination. Higher is better.
| Model | Non-Hallucination % | Tool-Call % | ||
|---|---|---|---|---|
| Prod (reasoning off) | Best (with reasoning) | Prod (reasoning off) | Best (with reasoning) | |
| gpt-5.5 | 84.8% | 88.0% | 75.6% | 88.3% |
| gpt-5.4 | 83.0% | 83.3% | 75.2% | 77.4% |
| gemini-3.1-pro | 82.6% | 83.6% | 85.7% | 85.9% |
| gpt-5.2 | 81.3% | 81.6% | 79.6% | 81.5% |
| claude-4.6-sonnet | 81.2% | 81.6% | 80.1% | 80.4% |
| glm-5.1 | 79.3% | 82.7% | 77.3% | 83.8% |
| gpt-5.1 | 75.7% | 81.0% | 78.2% | 83.7% |
| gemini-3.1-flash-lite | 74.4% | 77.7% | 69.0% | 75.8% |
| gemini-3-flash | 73.8% | 80.1% | 71.2% | 81.8% |
| gpt-4o | 72.8% | 72.8% | 63.6% | 63.6% |
| claude-4.5-haiku | 72.4% | 78.7% | 70.7% | 79.4% |
| gemini-2.5-pro | 72.3% | 77.2% | 72.9% | 80.6% |
| gemini-3.5-flash | 72.0% | 80.7% | 69.2% | 84.0% |
| claude-4.5-sonnet | 71.5% | 80.6% | 77.5% | 85.8% |
| gpt-4.1 | 71.5% | 71.5% | 62.2% | 62.2% |
| gpt-5 | 71.2% | 78.8% | 68.9% | 83.2% |
| gpt-5.4-mini | 70.7% | 71.3% | 57.1% | 60.2% |
| gpt-5-mini | 69.4% | 75.2% | 70.6% | 75.6% |
| o4-mini | 67.9% | 67.9% | 73.9% | 73.9% |
| gpt-5.4-nano | 66.2% | 66.3% | 57.5% | 59.1% |
| grok-4.3 | 65.8% | 76.3% | 54.6% | 72.1% |
| kimi-k2.6 | 63.5% | 63.5% | 66.3% | 66.3% |
| o3-mini | 62.7% | 62.7% | 59.0% | 59.0% |
| gemini-2.5-flash-lite | 59.8% | 75.2% | 47.0% | 70.3% |
| mercury-2 | 56.7% | 61.9% | 52.2% | 55.9% |
| gpt-5-nano | 53.9% | 57.6% | 54.5% | 56.1% |
| deepseek-v4-pro | 49.8% | 55.6% | 58.9% | 64.5% |
Prod is each model with reasoning off, or its lowest available setting. Best is its strongest reasoning setting. Models with matching columns (gpt-4o, gpt-4.1, kimi-k2.6, o4-mini, o3-mini) had a single setting evaluated.
A benchmark is only useful if it changes how you build. The gaps vCX-Hard exposes map directly onto features in the Retell platform, so you do not have to ship them.
Model choice is step one. The platform around the model is what turns a benchmark score into a deployment you can trust.
vCX-Hard is an early version and has real limits. Grading rests on an LLM judge panel, which carries its own biases. The cases are mined for difficulty, so scores reflect the hardest turns rather than average call quality. And the benchmark measures two specific failure modes, not the full experience of a call such as tone, latency, or interruption handling.
We will keep vCX-Hard updated as new models ship. Every launch sets off the same question in every team running voice agents: a new model is out, do we switch? vCX-Hard is built to answer that with current data rather than a guess.
Benchmarks are not for making numbers look good. They are for honest comparison. When one saturates, the field builds a harder one. vCX-Hard is how we choose models internally, and how we now answer the question customers actually ask, with evidence instead of a brand name. We will keep raising the bar as the models do.
See how much your business could save by switching to AI-powered voice agents.
Total Human Agent Cost
AI Agent Cost
Estimated Savings
A Demo Phone Number From Retell Clinic Office









