vCX-Hard: Avaliando os Principais Modelos de IA em Chamadas Reais de Centrais de Atendimento

Apresentamos o vCX-Hard, um benchmark da Retell que classifica os principais modelos em chamadas reais de central de atendimento, medindo duas capacidades que determinam se um agente de voz tem sucesso: manter-se ancorado na verdade e tomar a ação certa. Construído a partir de dados proprietários de chamadas em produção, o vCX-Hard avalia o desempenho dos modelos onde mais importa. Mesmo o melhor modelo de hoje alcança apenas cerca de 88% nos turnos mais difíceis, que é exatamente o motivo pelo qual a escolha do modelo importa.
Os clientes nos fazem uma pergunta mais do que qualquer outra: qual modelo devo usar para o meu agente de voz? Por muito tempo, a resposta interna honesta foi um nome e um dar de ombros. Para uma plataforma que roda milhões de chamadas reais de clientes, isso não é bom o suficiente.
Um agente de central de atendimento vive ou morre por duas habilidades, e apenas duas:
Os benchmarks públicos raramente testam ambos ao mesmo tempo, e quase nunca nas condições de uma chamada telefônica ao vivo. Os dados que conseguem fazer isso são difíceis de obter. Os próprios registros de chamadas de uma única empresa não são diversos o suficiente para classificar modelos com confiança. A Retell está sobre tráfego de produção real e diverso, em vários setores e implantações, no volume necessário para separar um modelo de outro. Esse é o único ingrediente de que um benchmark confiável de central de atendimento precisa, e é o único que a maioria das equipes não consegue montar.
O nome diz o que ele é. O v minúsculo é de voz (voice). CX é experiência do cliente (customer experience), o trabalho cotidiano de um agente de central de atendimento. Hard é o método: avaliamos apenas os turnos mais difíceis do tráfego real de produção, os momentos em que os modelos de fato se distinguem. Na distribuição completa de chamadas de produção, a maioria dos modelos de fronteira já alcança 90 por cento, o que não diz nada de útil. A fatia difícil é onde um benchmark prova o seu valor.
Cada caso é extraído de chamadas reais de produção, não escrito à mão nem gerado sinteticamente. Pontuamos os modelos nos dois eixos que decidem uma chamada:
Avaliamos 50 configurações abrangendo 27 modelos. Como os agentes de voz em produção rodam com o raciocínio desligado, por causa da latência, relatamos duas visões ao longo do texto: produção (raciocínio desligado, o que roda nas chamadas ao vivo) e melhor (raciocínio médio, um teto para quanto o raciocínio agregaria). O GPT-5.5 lidera ambas, alcançando 84,8 por cento de não alucinação em produção e 88,0 por cento no seu melhor. Nenhum modelo está perto de resolvido, que é exatamente o ponto.
Amostramos o tráfego de chamadas de produção entre 6 de fevereiro e 1º de maio de 2026, em janelas de 30 minutos a cada 15 dias aproximadamente, extraídas de organizações com mais de 1.000 chamadas nos três meses anteriores. Crucialmente, amostramos no nível da organização, para que algumas organizações de alto volume não dominem o conjunto. É isso que mantém a distribuição ampla entre implantações reais, em vez de enviesada para qualquer cliente.
Desse tráfego, selecionamos dois conjuntos de casos difíceis: um conjunto de alucinação de 2.075 casos e um conjunto de chamadas de ferramenta de 1.514 casos. Cada caso é extraído por meio de um pipeline de múltiplos estágios. Pré-classificadores leves sinalizam turnos candidatos (alegações numéricas, momentos pré-transferência, erros de ferramenta, chamadas repetidas ou ausentes), um classificador de LLM então confirma se uma falha real ocorreu e rotula sua categoria e severidade, uma segunda passagem reverifica o turno específico e, por fim, uma solução de referência correta é gerada para a avaliação.
A própria taxonomia de falhas é informativa. No lado da alucinação, o problema dominante não é exótico. Os agentes fabricam ou declaram incorretamente políticas muito mais do que qualquer outra coisa.

As falhas de chamada de ferramenta se agrupam de forma igualmente compacta. Dos 1.514 casos, as duas maiores categorias são deixar de fazer uma chamada necessária (897) e disparar uma desnecessária (520). A seleção da ferramenta errada é quase inexistente (2 casos). Em outras palavras, os modelos raramente escolhem a ferramenta errada. Eles falham no julgamento: saber quando agir e quando se conter.
A avaliação usa um conselho de LLMs: um painel de modelos de fronteira líderes que pontua cada caso em relação a uma rubrica descritiva e a uma solução de referência gerada. Usar vários juízes fortes em vez de um só evita que a avaliação herde os pontos cegos de um único modelo, e as discordâncias são reconciliadas dentro do painel.
Como as pontuações absolutas variam com a rubrica e os juízes, tratamos a classificação, não o número exato, como o sinal.
A pontuação máxima é de cerca de 88 por cento, e isso é proposital. Se avaliássemos na distribuição completa de produção, quase todo modelo de fronteira ficaria acima de 90 por cento e o ranking não diria nada. Chamadas fáceis são fáceis para todos.
Então o vCX-Hard é construído a partir dos turnos mais difíceis, os momentos em que os modelos de fato divergem. É assim que todo benchmark sério funciona. Um benchmark de matemática usa problemas de competição, não a aritmética que um usuário típico digita. O objetivo não é um número lisonjeiro. O objetivo é um número que você possa comparar entre modelos, e ao longo do tempo, à medida que novos modelos são lançados.
Mostramos cada ranking de duas formas: produção, com o raciocínio desligado, que é o que roda nas chamadas ao vivo, e melhor, cada modelo na sua configuração de raciocínio mais forte, que mostra o teto. Na não alucinação, o GPT-5.5 lidera ambas. Em produção, a linha do GPT-5 e o gemini-3.1-pro ficam no topo; ligar o raciocínio eleva os mesmos nomes alguns pontos e reorganiza a disputa atrás deles.
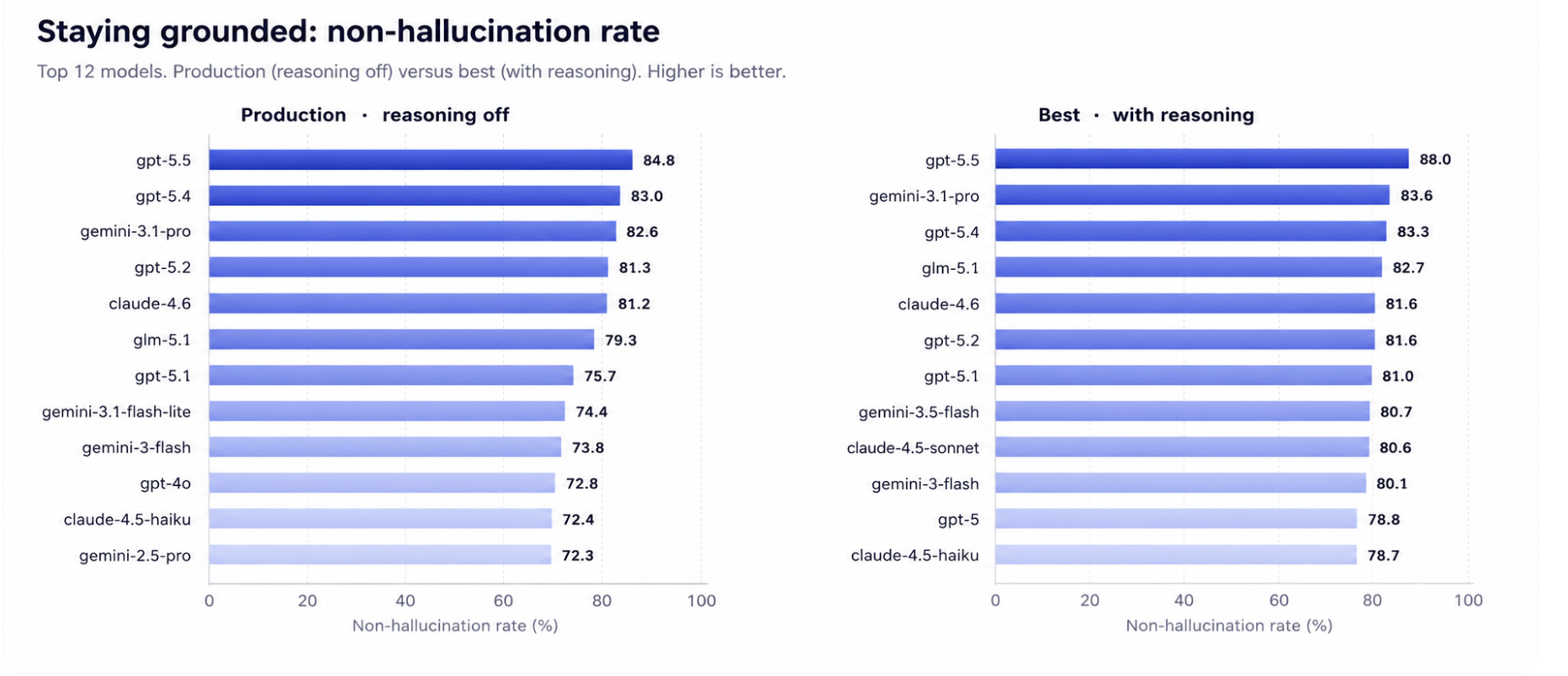
A correção de chamadas de ferramenta é onde as duas visões mais divergem. Com o raciocínio ligado, o GPT-5.5 lidera. Mas em produção, onde de fato roda, a chamada de ferramenta do GPT-5.5 cai de 88,3 para 75,6 por cento, e o gemini-3.1-pro se torna o melhor em chamadas de ferramenta por uma margem clara, mantendo 85,7 por cento com o raciocínio desligado. Se o seu agente roda com o raciocínio desligado, o modelo mais forte não é o mesmo.

Três padrões se destacam em todo o conjunto.
1. O raciocínio é a diferença entre as duas visões. Ligar o raciocínio eleva as pontuações em quase todos os modelos, em cerca de 5 pontos em média para a não alucinação. O GPT-5.5 sobe de 84,8 para 88,0 por cento quando raciocina antes de falar. O custo é a latência, que é por que a maioria dos agentes de produção a deixa desligada, e por que a visão de produção é a que se deve planejar.

2. Ancoragem e ação são habilidades diferentes. Os dois eixos não classificam da mesma forma. Um modelo forte em ancoragem pode ser mediano em chamadas de ferramenta, e vice-versa. O GPT-5.4 fica perto do topo em ancoragem, mas fora do top dez em chamadas de ferramenta, enquanto o claude-4.5-sonnet é o oposto. Escolher um modelo é, na verdade, uma questão de qual falha os seus clientes podem menos se dar ao luxo de ter.
3. Nenhum modelo está seguro ainda. Mesmo no seu melhor, o líder ainda erra cerca de um em cada oito dos turnos mais difíceis em cada eixo, e em produção erra mais. A distância entre uma pontuação de benchmark e uma implantação em que você pode confiar é exatamente o trabalho que a plataforma faz por cima do modelo.
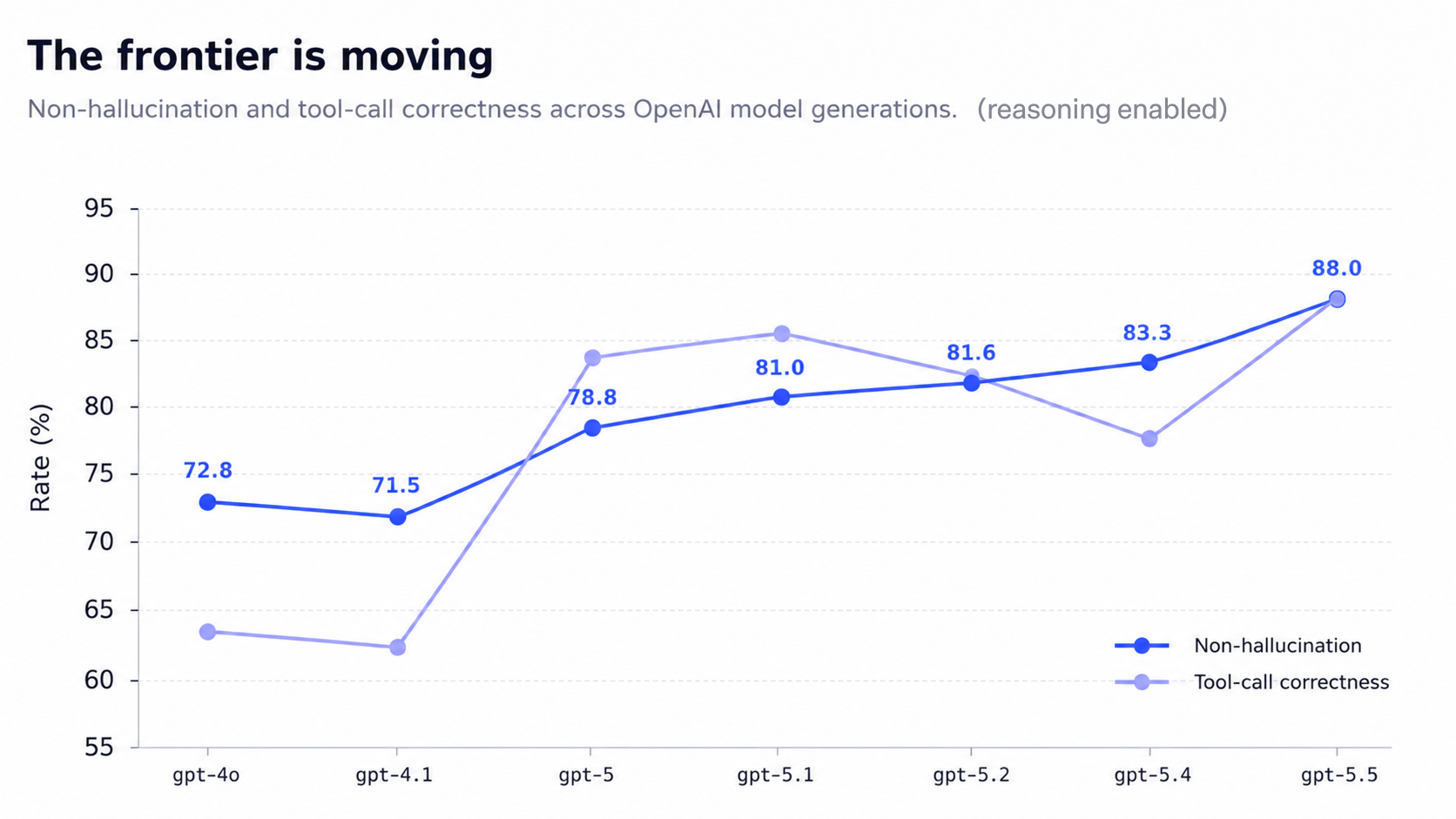
Olhando para as gerações de modelos, a fronteira está se movendo na direção certa. Do GPT-4o ao GPT-5.5, a não alucinação subiu de 72,8 para 88,0 por cento, com as chamadas de ferramenta melhorando em um arco semelhante.
Produção (raciocínio desligado, o que roda ao vivo) e melhor (configuração de raciocínio mais forte) para cada modelo, ordenado pela não alucinação em produção. Maior é melhor.
| Modelo | Não Alucinação % | Chamada de Ferramenta % | ||
|---|---|---|---|---|
| Prod (sem raciocínio) | Melhor (com raciocínio) | Prod (sem raciocínio) | Melhor (com raciocínio) | |
| gpt-5.5 | 84.8% | 88.0% | 75.6% | 88.3% |
| gpt-5.4 | 83.0% | 83.3% | 75.2% | 77.4% |
| gemini-3.1-pro | 82.6% | 83.6% | 85.7% | 85.9% |
| gpt-5.2 | 81.3% | 81.6% | 79.6% | 81.5% |
| claude-4.6-sonnet | 81.2% | 81.6% | 80.1% | 80.4% |
| glm-5.1 | 79.3% | 82.7% | 77.3% | 83.8% |
| gpt-5.1 | 75.7% | 81.0% | 78.2% | 83.7% |
| gemini-3.1-flash-lite | 74.4% | 77.7% | 69.0% | 75.8% |
| gemini-3-flash | 73.8% | 80.1% | 71.2% | 81.8% |
| gpt-4o | 72.8% | 72.8% | 63.6% | 63.6% |
| claude-4.5-haiku | 72.4% | 78.7% | 70.7% | 79.4% |
| gemini-2.5-pro | 72.3% | 77.2% | 72.9% | 80.6% |
| gemini-3.5-flash | 72.0% | 80.7% | 69.2% | 84.0% |
| claude-4.5-sonnet | 71.5% | 80.6% | 77.5% | 85.8% |
| gpt-4.1 | 71.5% | 71.5% | 62.2% | 62.2% |
| gpt-5 | 71.2% | 78.8% | 68.9% | 83.2% |
| gpt-5.4-mini | 70.7% | 71.3% | 57.1% | 60.2% |
| gpt-5-mini | 69.4% | 75.2% | 70.6% | 75.6% |
| o4-mini | 67.9% | 67.9% | 73.9% | 73.9% |
| gpt-5.4-nano | 66.2% | 66.3% | 57.5% | 59.1% |
| grok-4.3 | 65.8% | 76.3% | 54.6% | 72.1% |
| kimi-k2.6 | 63.5% | 63.5% | 66.3% | 66.3% |
| o3-mini | 62.7% | 62.7% | 59.0% | 59.0% |
| gemini-2.5-flash-lite | 59.8% | 75.2% | 47.0% | 70.3% |
| mercury-2 | 56.7% | 61.9% | 52.2% | 55.9% |
| gpt-5-nano | 53.9% | 57.6% | 54.5% | 56.1% |
| deepseek-v4-pro | 49.8% | 55.6% | 58.9% | 64.5% |
Prod é cada modelo com o raciocínio desligado, ou a sua configuração mais baixa disponível. Melhor é a sua configuração de raciocínio mais forte. Modelos com colunas idênticas (gpt-4o, gpt-4.1, kimi-k2.6, o4-mini, o3-mini) tiveram uma única configuração avaliada.
Um benchmark só é útil se mudar a forma como você constrói. As lacunas que o vCX-Hard expõe mapeiam diretamente para recursos da plataforma Retell, para que você não precise desenvolvê-los.
A escolha do modelo é o passo um. A plataforma em torno do modelo é o que transforma uma pontuação de benchmark em uma implantação em que você pode confiar.
O vCX-Hard é uma versão inicial e tem limites reais. A avaliação se apoia em um painel de juízes de LLM, que carrega seus próprios vieses. Os casos são extraídos por dificuldade, então as pontuações refletem os turnos mais difíceis, e não a qualidade média da chamada. E o benchmark mede dois modos específicos de falha, não a experiência completa de uma chamada, como tom, latência ou tratamento de interrupções.
Manteremos o vCX-Hard atualizado à medida que novos modelos forem lançados. Todo lançamento dispara a mesma pergunta em toda equipe que roda agentes de voz: saiu um novo modelo, a gente troca? O vCX-Hard foi feito para responder isso com dados atuais em vez de um palpite.
Benchmarks não servem para fazer os números parecerem bons. Servem para uma comparação honesta. Quando um satura, o campo constrói um mais difícil. O vCX-Hard é como escolhemos modelos internamente, e como agora respondemos à pergunta que os clientes de fato fazem, com evidências em vez de uma marca. Vamos continuar elevando a barra à medida que os modelos elevam.
Veja quanto seu negócio poderia economizar ao migrar para agentes de voz com IA.
Total Human Agent Cost
AI Agent Cost
Estimated Savings
Um número de telefone de demonstração do consultório da Retell Clinic








